线性链表的运算主要有以下几个:
• 在线性链表中包含指定元素的结点之前插入一个新元素。
• 在线性链表中删除包含指定元素的结点。
• 将两个线性链表按要求合并成一个线性链表。
• 将一个线性链表按要求进行分解。
• 逆转线性链表。
• 复制线性链表。
• 线性链表的排序。
• 线性链表的查找。
本小节主要讨论线性链表的插入与删除。
1.在线性链表中查找指定元素
在对线性链表进行插入与删除的运算中,总是首先需要找到插入或删除的位置,这就需要对线性链表进行扫描查找,在线性链表中寻找包含指定元素值的前一个结点。当找到包含指定元素的前一个结点后,就可以在该结点后插入新结点或删除该结点后的一个结点。
在非空线性链表中寻找包含指定元素值 x 的前一个结点 p 的基本方法如下:
从头指针指向的结点开始往后沿指针进行扫描,直到后面已没有结点或下一结点的数据域为 x 为止。因此,由这种方法找到的结点 p 有两种可能:当线性链表中不存在包含元素 x 的结点时,则找到的 p 为线性链表中的最后一个结点号。
2.线性链表的插入
线性链表的插入是指在链式存储结构下的线性表中插入一个新元素。
为了要在线性链表中插入一个新元素,首先要给该元素分配一个新结点,以便用于存储该元素的值。新结点可以从可利用栈中取得。然后将存放新元素值的结点链接到线性链表中指定的位置。
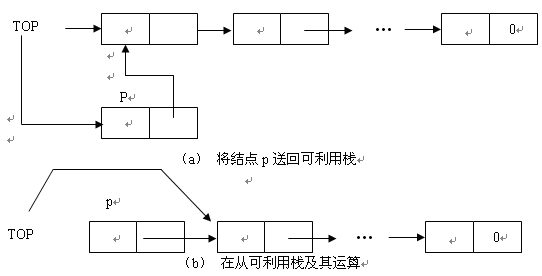
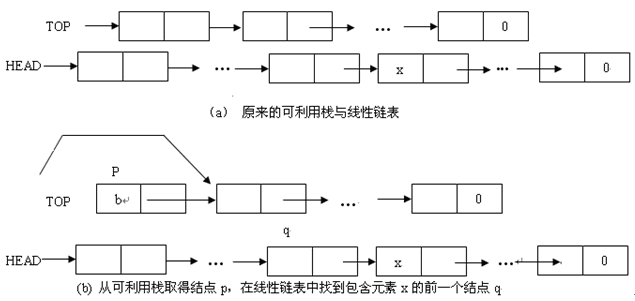
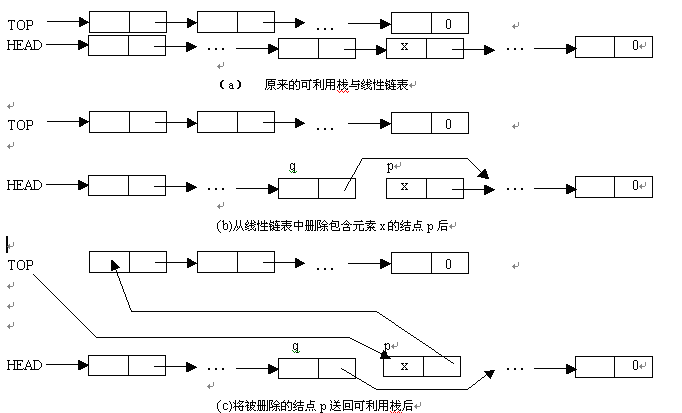
假设可利用栈与线性链表如图 1.23 ( a )所示。现在要在线性链表中包含元素 x 的结点之前插入一个新元素 b 。其插入过程如下:
• 从可利用栈取得一个结点,设该结点号为 p (即取得结点的存储序号存放在变量 p 中),并置结点 p 的数据域为插入的元素值 b 。经过这一步后,可利用栈的状态如图 1.23 ( b )所示。
• 在线性链表中寻找包含元素 x 的前一个结点,设该结点的存储序号为 q 。
线性链表如图 1.23 ( b )所示。
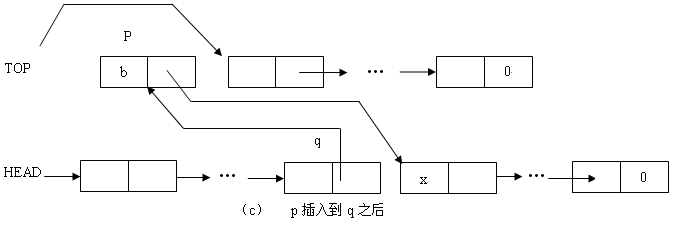
• 最后将结点 p 插入到 q 之后。为了实现这一步,只要改变以下两个结点的指针域内容:
• 使结点 p 指向包含元素 x 的结点(即结点 q 的后件结点)。
• 使结点 q 的指针域内容改为指向结点 p 。
这一步的结果如图 1.23 ( c )所示。此时插入就完成。
图1.23 线性链表的插入
由线性链表的插入过程可以看出,由于插入的新结点取自于可利用栈,因此,只要可利用栈不空,在线性链表插入时总能取到存储插入元素的新结点,不会发生“上溢”的情况。而且,由于可利用栈是公用的,多个线性链表可以共享它,从而很方便地实现了存储空间的动态分配。另外,线性链表在插入过程中不发生数据元素移动的现象,只需改变有关结点的指针即可,从而提高了插入的效率。
3.线性链表的删除
线性链表的删除是指在链式存储结构下的线性表中删除包含指定元素的结点。
为了在线性链表中删除包含指定元素的结点,首先要在线性链表中找到这个结点,然后将要删除结点放回到可利用栈。
假设可利用栈与线性链表如图 1.24 ( a )所示。现在要在线性链表删除包含元素 x 的结点,其删除过程如下:
( 1 )在线性链表中寻找包含元素 x 的前一个结点,设该结点序号为 q.
( 2 )将结点 q 后的结点 p 从线性链表中删除,即让结点 q 的指针指向包含元素 x 的结点 p 的指针指向的结点。
经过上述两步后,线性链表如图 1.24 ( b )所示 .
( 3 )将包含元素 x 的结点 p 送回可利用栈。经过这一步后,可利用栈的状态如图 1.24 ( c )所示。此时,线性链表的删除运算完成。
图 1.24 线性链表的删除
从线性链表的删除过程可以看出,在线性链表中删除一个元素后,不需要移动表的数据元素,只需改变被删除元素所在结点的指针域即可。另外,由于可利用栈是用于收集计算机中所有的空闲结点,因此,当从线性链表中删除一个元素后,该元素的存储结点变为空闲,应该将空闲结点送回到可利用栈。
1.5.3 循环链表及其基本运算
前面所讨论的线性链表中,其插入与删除的运算虽然比较方便,但还存在一个问题,在运算过程中对于空表和第一个结点的处理必须单独考虑,使空表与非空表的运算不统一。为了克服线性链表的这个缺点,采用一种链接方式,即循环链表( circular linked list )的结构。
循环链表的结构与前面所讨论的线性表相比,具有以下两个特点:
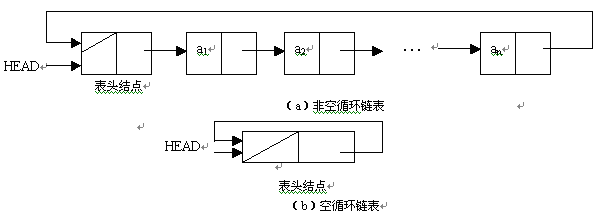
( 1 )在循环的链表中增加了一个表头结点,其数据域为任意或者根据需要来设置,指针域指向线性表的第一个元素的结点。循环链表的头指针指向表头结点。
( 2 )循环链表中最后一个结点的指针域不是空,而是指向表头结点。即在循环链表中,所有结点的指针构成了一个环状链。
图 1.25 是循环链表的示意图。其中图 1.25 ( a )是一个非空的循环链表,图 1.25 ( b )是一个空的循环链表。在此,所谓的空表与非空表是针对线性表中的元素而言。
图1.25 循环链表的逻辑状态
在循环链表中,只要指出表中任何一个结点的位置,就可以从它出发访问到表中其他所有的结点,而线性单链表做不到这一点。
另外,由于在循环链表中设置了一个表头结点,因此,在任何情况下,循环链表中至少有一个结点存在,从而使空表与非空表的运算统一。
循环链表的插入和删除的方法与线性单链表基本相同。但由循环链表的特点可以看出,在对循环链表进行插入和删除的过程中,实现了空表与非空表的运算统一。